Point Arena
Probing Multimodal Grounding Through Language-Guided Pointing
Point-Bench
Standardized evaluation of precise spatial alignment between language and vision
| Rank | Model | Affordance | Spatial | Reasoning | Steerability | Counting | Average |
|---|
Loading data...
Point-Bench Gallery
.jpg)
_overlay.png)


















Dataset Analysis
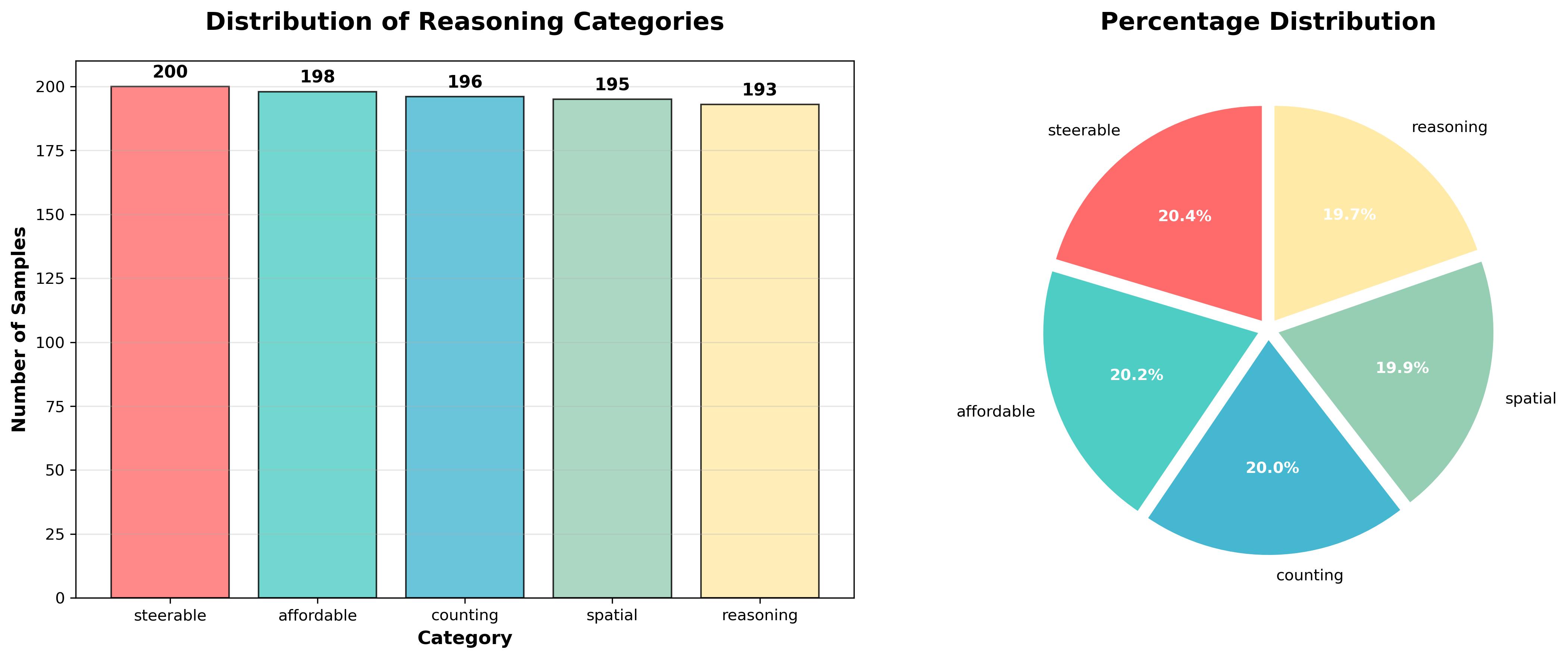
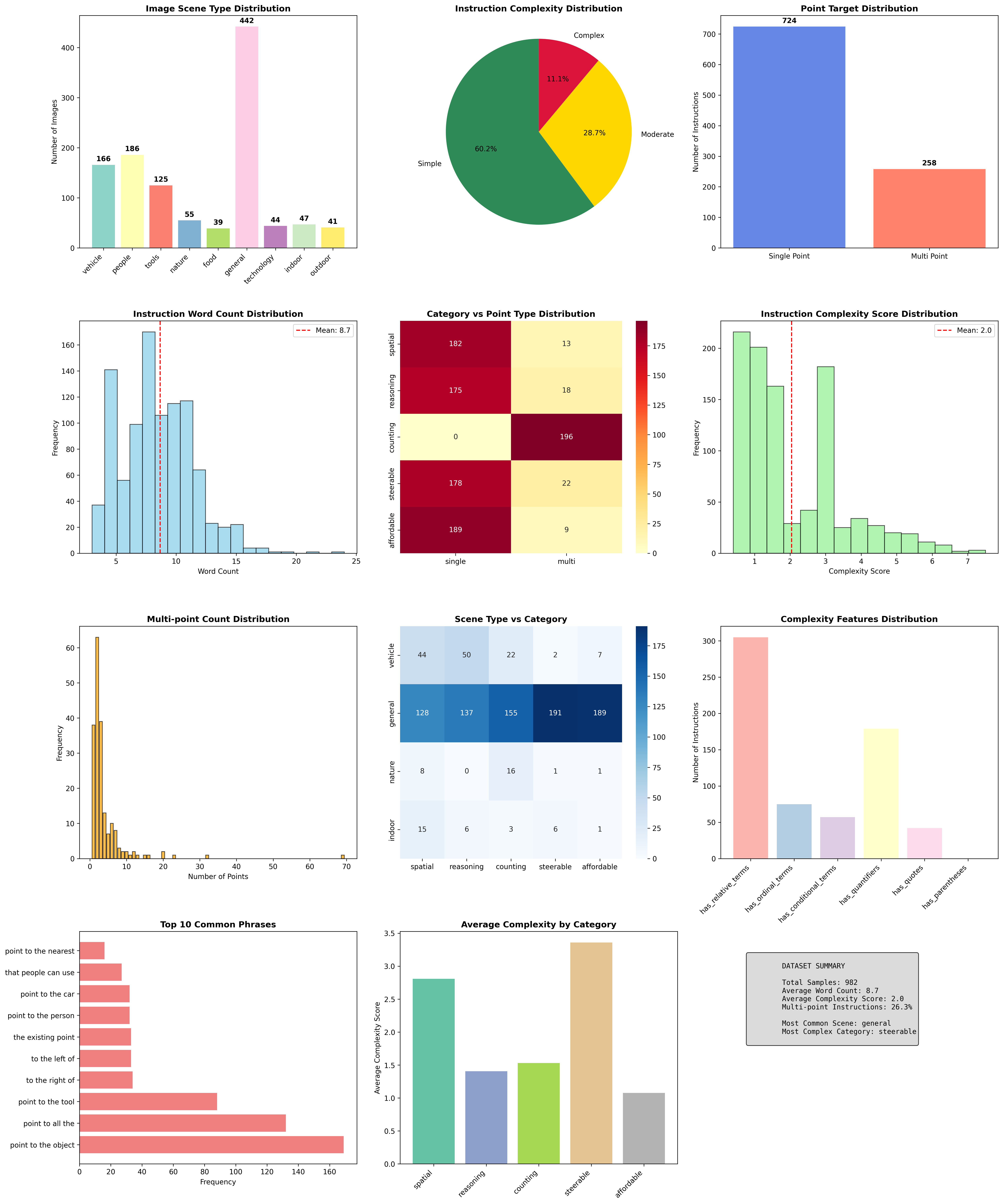
Point-Battle
Performance disparities across model types and prompt strategies
| Rank | Model | Elo Rating | Wins | Losses | Games | Win Rate | Lower CI | Upper CI |
|---|
Loading data...
Point-Act
Diverse datasets for standardized scenarios and rigorous evaluation protocols
| Challenge | Success Rate | SUS Score |
|---|
Loading data...
About Point Arena
Our Mission
Point Arena is the first open and unified evaluation platform specifically designed to assess language-guided pointing capabilities in multi-modal large language models (MLLMs).
Despite recent advances in visual reasoning, existing benchmarks lack fine-grained grounding tasks that require precise spatial alignment between language and vision. Point Arena addresses this gap by offering standardized scenarios, diverse datasets, and rigorous evaluation protocols.
Research Findings
- Performance Disparities: Significant differences across model types and prompt strategies
- Current Limitations: Identified challenges in spatial reasoning and grounding fidelity
- Future Directions: New paths for multi-modal alignment research
Point Arena is publicly available and aims to facilitate reproducible and transparent progress in multi-modal understanding.
Citation
@misc{cheng2025pointarenaprobingmultimodalgrounding,
title={PointArena: Probing Multimodal Grounding Through Language-Guided Pointing},
author={Long Cheng and Jiafei Duan and Yi Ru Wang and Haoquan Fang and Boyang Li and Yushan Huang and Elvis Wang and Ainaz Eftekhar and Jason Lee and Wentao Yuan and Rose Hendrix and Noah A. Smith and Fei Xia and Dieter Fox and Ranjay Krishna},
year={2025},
eprint={2505.09990},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2505.09990},
}